Pizza time! (No turtles please)
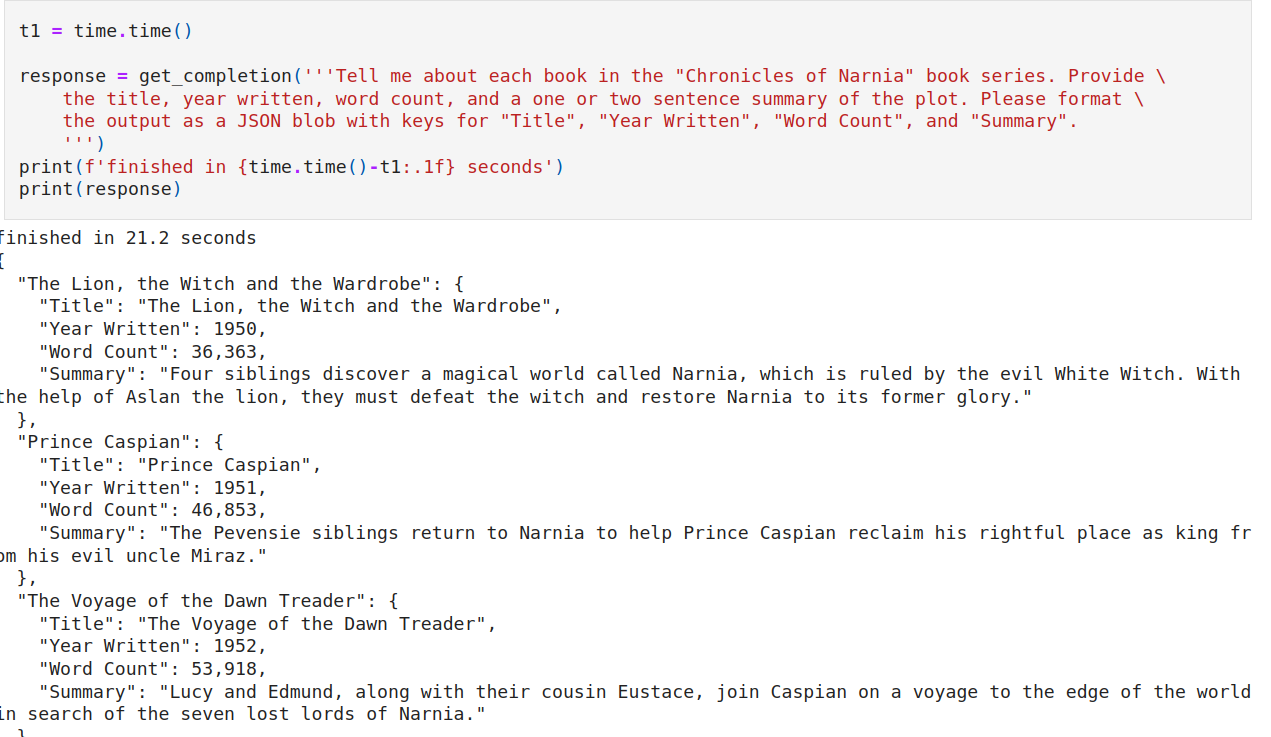
The DeepLearning.AI short course on prompt engineering culminates with the demo of a pizza OrderBot. The bot is able to answer questions about the menu, gather the order, and summarize the whole thing at the end, complete with the correct total price. The menu in this example is represented in plain text within a system role message (Figure 1).
 |
| Figure 1: System role message with menu |
Figure 2 shows an example of a complete order executed by the bot.
 |
| Figure 2: Sample order |
One well-known problem with LLMs, however, is their tendency to hallucinate. Asking about details not provided in the prompt causes the model to make up details based on its original training. This can be dangerous in production applications because even inaccurate responses can sound reasonable. Figure 3 shows examples of hallucinations about details not provided in the pizza menu.
 |
| Figure 3: Hallucinations |
The errors in these specific examples are fixable by adding more details (diameters of pizzas, sizes of drinks) to the menu text in the prompt. Fool-proofing the menu would be an iterative process that could potentially cause regressions as menu complexity increases.
Querying structured data
Here, I explore if hallucinations are reduced when the menu is structured in SQL tables instead of plain text. I hypothesize that well-chosen table and column names would act as metadata to help the LLM understand how and whether to answer a given question.
To set up the database, dataframes were made for each category of item (pizza, topping, side item, and drink). They were first prototyped as pandas dataframes and then loaded into a SQLite database with SQLAlchemy. The table schemas consist of the item name, price, and item description. Figure 4 shows the full content of the tables.
 |
| Figure 4: Pizza menu database |
ChatGPT was connected to the database via LangChain, an exciting new open-source framework for incorporating LLMs into applications. The project provides modular components for a) connecting LLMs to external data sources and b) accomplishing higher-level tasks like Q&A sessions. The components can be chained together to create arbitrarily complex applications. The short, and currently free, LangChain course from DeepLearning.AI provides an accessible and comprehensive introduction.
LangChain provides a SQLDatabaseChain component for querying data in any database compatible with SQLAlchemy. The tool implements established best practices for prompting an LLM to write SQL queries, although further customization of the prompt is possible. The minimal steps for setting up the SQLDatabaseChain include connecting to the database and initializing an LLM (Figure 5). After experimenting with my own prompt, I adopted the default prompt.
 |
| Figure 5: Using SQLDatabaseChain |
I expect the SQL chain to perform at least as well as the version with the plain-text menu, so I start by presenting the three inputs that caused hallucinations in Figure 3. Impressively, the SQL chain answers all the questions correctly and without hallucinating false details. Figure 6 shows the results. Some of the output remarks (e.g., "The sizes and their corresponding dimensions are not provided in the database.") are not necessarily things that should be shown to end users, and prompting the model to use a different tone would be worthwhile.
 |
| Figure 6: Questions now answered correctly with a SQL database |
Some comments are in order:
- These examples demonstrate the ability of the LLM to examine the data schema and write the SQL needed to efficiently solve the problem. In each case, the SQL chain is following the process specified in the prompt: identify the question, write the SQL query, get the query output, and formulate the final answer.
- In the first example (number and sizes of pizza), the LLM inferred from the Price_Large, Price_Medium, and Price_Small fields that there the three pizza sizes are Large, Medium, and Small. It did not confuse the prices as measurements of size (although, see below where this does happen), and it correctly stated that information on dimensions is not available.
- In the second example (number and sizes of bottled water), the LLM found only one row and read from the description that the size is 20 ounces. The Price_Medium and Price_Small columns were NULL, but it is not clear this was used in the answer. Asking a related question on the number, size, and cost of Coke returns a detailed and correct answer, which is reassuring.
- In the third case (Greek salad as a topping), the LLM joined the
pizzas andtoppings tables together, found no rows where 'Greek salad' was a topping, and concluded it was not possible.
As impressive as the above results are, the LLM still gets fooled by seemingly simple questions. When asked simply about the diameters of pizza size (which was answered correctly above as part of a longer question), the LLM confuses the price values for pizza dimensions. When asked a second time and reminded that the price values are dollars and not dimensions, it correctly reports that it cannot answer the question.
 |
| Figure 7: Confusing dollars with inches |
As a final example, I ask about the size of a small cheese pizza topped with mushrooms and sausage. The chain manages to join the pizzas and toppings tables together in a way that returns 0 rows (Figure 8). This is disappointing since the original chatbot with the text menu could answer such a question. Non-invasive ways to fix this text-to-SQL brittleness include customizing the prompt instructions and/or including sample rows in the prompt.
 |
| Figure 8: Incorrect price quote |
In this case, I tried out the SQLDatabaseSequentialChain which first examines the schema to decide which tables are relevant and then calls the SQLDatabaseChain for the relevant tables. The result is correct and is shown in Figure 9. The better outcome is not a fluke. The sequential chain consistently outperforms the simpler chain in repeat trials. It might be that the sequential chain is giving the LLM a more detailed examination of the table schemas, so that it is able to write more relevant SQL.
 |
| Figure 9: Correct price quote |
Better ingredients, better PizzaBot
Using the lessons learned above, I now assemble a new pizza OrderBot more robust than the one above (Figures 1-3). In addition to working off a database representation of the pizza menu (Figure 4), I would like the bot to be able to send a summary of the order to the user's email. The bot will have to converse with the user in real-time and know when to access tools for searching the database and sending the email.
The LangChain Agent interface is able to select which, if any, of the available tools should be called based on the user input.
Referencing detailed examples (especially this one) from LangChain's documentation, I was able prototype the desired functionality in my own custom agent.
The final solution consists of the following components:
- A conversational agent (langchain.agents.ConversationalAgent) with a custom prompt spelling out its role as an OrderBot.
- Conversation memory buffers (langchain.memory.ConversationBufferMemory, langchain.memory.ReadOnlySharedMemory)
- A SQLDatabaseChain for querying the pizza database (see Figures 5 and 9 for details)
- Two instances of LLMChain: one for the agent and one for producing the order summary.
- A Custom email function: input is a single pipe-delimited string containing order summary and recipient email address.
- An underlying LLM (gpt-3.5-turbo)
The agent needs access to tools for database search (SQLDatabaseSequentialChain), order summary (LLMChain), and sending emails (custom function). The order summary tool is just an LLMChain with a custom prompt. Given the chat history (via an instance of ReadOnlySharedMemory), it will summarize the name and price of each item, as well as the total price. The code for customizing this chain is shown in Figure 10.
 |
| Figure 10: LLMChain order summary tool |
The tools are set up as a list of langchain.agent.Tool objects. Each Tool instance knows its own name (e.g., 'Menu Search'), what function it points to, and has a text description the LLM parses when deciding which tool to call. Figure 11 shows the final configuration of the tools. Note the Order Summary tool additionally has the return_direct=True parameter, which returns the output of the tool directly to the agent (otherwise the LLM would read and rephrase the order summary).
 |
| Figure 11: The OrderBot's tools |
The Send Email tool (Figure 12) is the most complex. I specify in the description that the input is one pipe-delimited string containing the order summary text and the user's email. The send_message function then parses the substrings before it formats the email. Correct output from Send Email requires that Order Summary be successfully called first.
 |
| Figure 12: How emails are sent |
To make the OrderBot more self-aware about its role in the pizza ordering process, the ConversationalAgent's prompt needs to be edited. The default prompt includes a prefix, a description of available tools, and a suffix. I edit the prefix to explain the OrderBot's function. The tool list is automatically populated from the existing list of tools. The suffix has placeholders for the chat history, user input, and a scratchpad for the agent to compose a response. Figure 13 shows the code for updating the prompt while Figure 14 shows the fully formatted prompt template.
 |
| Figure 13: Customizing the agent's prompt |
 |
| Figure 14: Final agent prompt template |
As shown in Figure 15, the final agent chain (agent_chain) comes from bringing the components together in the langchain.agents.AgentExecutor.from_agent_and_tools method. Note, custom agent (agent) gets the custom prompt (agent_prompt) by way of an LLMChain. To prevent any parsing errors from causing a problem, the agent_chain.handle_parsing_errors parameter is set to True.
 |
| Figure 15: Defining the final agent (agent_chain) |
The pizza OrderBot is finally ready to use (e.g., agent_chain.run('What pizzas are available?')). The OrderBot turned out to be friendly, helpful, and addressed me by name. It could answer questions about the menu from the database exactly as shown above. Figure 16 shows an example of a correctly handled order. Figure 17 shows the email summary that was sent.
 |
| Figure 16: Sample conversation |
 |
| Figure 17: Email order summary |
I am largely satisfied with the prototype OrderBot. I experienced some difficulty formatting the email content. Attempts to format the order summary as an HTML table did succeed consistently. Getting the LLM to use some HTML (e.g., line breaks) would be helpful for summarizing long orders.
Summary
In this article, I have examined ChatGPT's ability to query and reason about tabular data. I found some indication that tabular data (a pizza menu) stored as plain text can inspire LLM hallucinations. Splitting the menu into multiple database tables seems to mitigate, but not eliminate, hallucinations. Finally, a prototype OrderBot capable of reading from a database and sending an email was presented. The OrderBot code is a template that can be repurposed for other custom chatbots.
Note: This article was produced with LangChain 0.0.220 and ChatGPT gpt-3.5-turbo-0301.