It has been over 6 months since the public release of ChatGPT in November 2022. The service was an immediate hit. As the most sophisticated example of a large language model (LLM) to date, the Internet wasted no time in interrogating its capabilities. As LLMs mature, dependence on such AI in daily life could increase dramatically.
The interactive web app is the easiest way for users to leverage ChatGPT right now. Novel future applications will require integration into devices or services having access to cloud-hosted models through APIs.
OpenAI provides a ChatGPT API for Python and node.js, and the broader community maintains libraries for other languages. Apart from the official documentation, another great way to learn is through the short ChatGPT courses currently on offer for free by DeepLearning.AI. As a new user to the API, the most surprising takeaway from the courses was that basic Python skills combined with the OpenAI API are sufficient to build new, ChatGPT-powered systems.
This article memorializes the key lessons I learned about using OpenAI's ChatGPT API. It is intended to be a reference for myself and a tutorial for new users to the API. The resources from the short courses are available here, and the original examples produced for this article are here.
Basic setup and authentication
Getting started in Python requires two steps:
- Installing the OpenAI module (pip install openai);
- Acquiring an API key.
In code, the API needs to be aware of the API key. It is not recommended to hard code the key in the code itself, and such code should never be submitted to a public repository. A simple alternative is to store the API in a local file called .env and to use the dotenv module (pip install dotenv) to detect the file and load the key as an environment variable. Figure 1 provides an example of how this can work:
 |
| Figure 1 |
Your first API call
Everything is now in place to start talking to ChatGPT. The ChatCompletion object creates a model response given a chat conversation. The chat conversation can be a single prompt or an entire chat history. In either case, the model parses the text and returns the most likely response.
Figure 2 shows a helper function for obtaining the response for a single prompt (i.e., input message). Follow-up calls with different messages will be treated as different conversations. This is unlike the web app where history is preserved within each separate conversation.
 |
| Figure 2 |
The model argument configures which language model to use. The GPT-3.5 model family can generate natural language and computer code. Of these, gpt-3.5-turbo is recommended as the best performance per cost ($0.002 per 1K tokens, or approximately 750 words). The full list of available models is here.
Secondly, the temperature argument controls the randomness of the response. Allowable values are in the range [0, 2] and lower values correspond to less randomness. Even at temperature 0, however, the model is mostly but not entirely deterministic.
The ChatCompletion call returns a particular kind of object (openai.openai_object.OpenAIObject) that contains the desired response plus additional meta data. From the full output (response), we want only a small piece, response.choices[0].message["content"]. Figure 3 shows the full response and, at the very bottom, the desired relevant output.
 |
| Figure 3 |
The input prompt can be 'engineered' to maximize the utility of the single output message ("prompt engineering" is an emerging new skill in the application of LLMs). For example, we can tell ChatGPT to include more fields (year written, short summary) and to format the output as a JSON object. If we were interested in using this as a Python object, we could convert with Python's JSON utilities. See Figure 4 for the result.
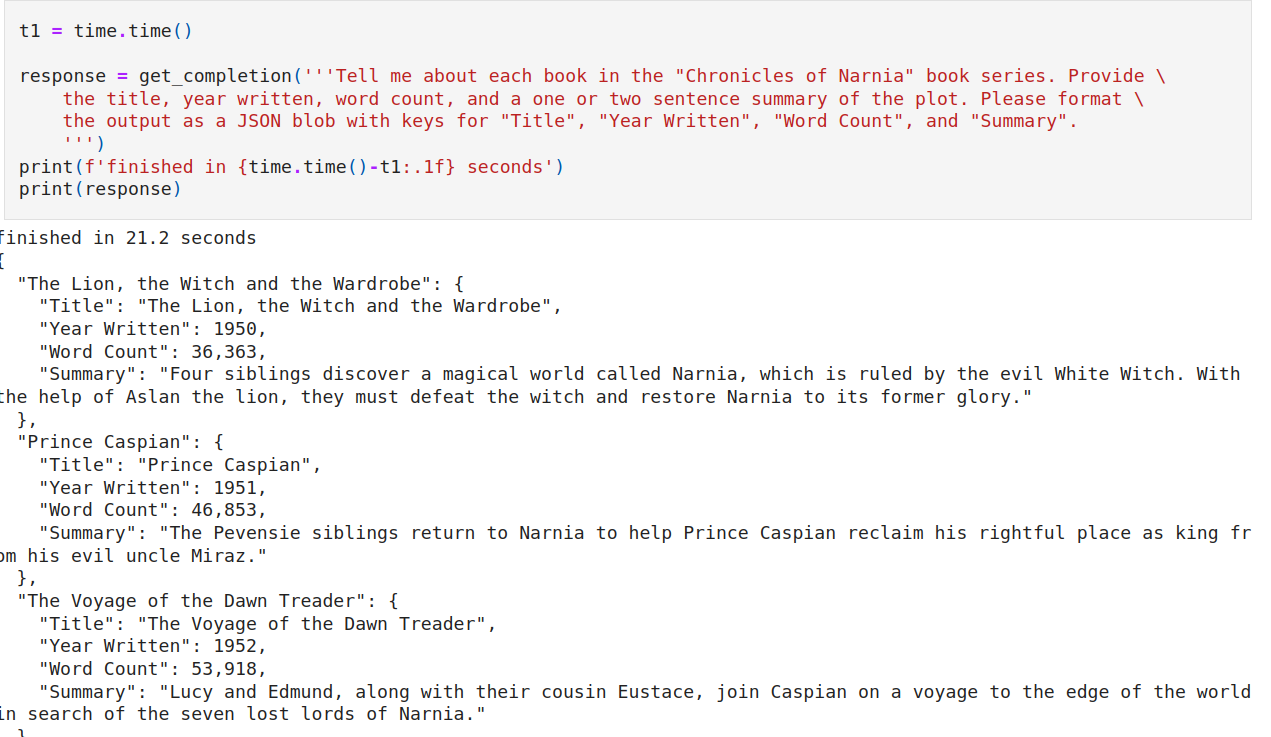 |
| Figure 4 |
This example highlights the importance of writing clear and specific instructions, which can include asking for structured output.
Multi-message chats
The ChatGPT model is stateless. Producing coherent conversations requires that at least some previous messages in the conversation be uploaded every time (increasing the number of tokens used) for the model for generate the next most likely response. The illusion of continuity is created at the expense of each API call becoming slightly more costly as a conversation unfolds.
In the above get_completion function (Figure 1), the user prompt is formatted into a list (messages) of dictionaries. Each dictionary encodes one message (content) and the source (role), which indicates the source of each piece of dialog. Role has one of three values: user (the human), assistant (the chatbot), and system (context for the assistant not meant to be visible to the user).
Figure 5 demonstrates passing multiple messages to the ChatGPT. In this case, the system role is instructing the assistant that is is to speak like Shakespeare, and that the user cannot override that style. The user then asks to hear a joke in a different style. The model apologizes that it must stick to the specified original style and then delivers a four-line joke complete with rhyme.
 |
| Figure 5 |
With this in mind, it is surprisingly simple to create a chatbot within a Jupyter notebook. In the example below (Figure 6), I have attempted to recreate the famous Duck season versus Rabbit season debate between Bugs Bunny and Daffy Duck. The Assistant is Daffy Duck, and the User is Bugs Bunny. Elmer Fudd is standing by with his rifle. The chat window widget is a panel widget. Source code for the chat is here.
 |
| Figure 6 |
Reasoning about math word problems
In this next section, let's explore whether ChatGPT can handle word problems. The answer is "yes, if prompted suitably".
I developed exercises that present options for eating out versus cooking at home. The model is supposed to evaluate each option and decide which is cheaper. In addition to choosing the right option, the model also verbalizes the cheaper option and outputs the amount saved daily and annually.
Figure 7 shows my first attempt (V1) at a prompt for the base case (eating out costs 15 dollars per meal while eating at home is 5 dollars per meal; the user always eats three times a day). ChatGPT gets the right answer (eating at home; annual savings of 365*3*($15 - $5) = $10,950). Note that it is useful in many contexts to inform the model that the user's prompt will be specially marked by delimiters such as triple backticks (```).
 |
| Figure 7 |
Asking the same question in a second way reveals a weakness in the prompt. In Figure 8, I present the cost of eating at home in units of cents (1/100 dollars), hoping to confuse the system. The model ends of doing the calculation in units of cents, and the output savings are quoted in cents. While this is not technically wrong, it can be considered incorrect since it is atypical to express amounts exceeding one dollar in cents.
 |
| Figure 8 |
Figure 9 shows the second version (V2) of the prompt in which the model is told to calculate in dollars and make the decision based on the total number of dollars spent per day. The description for the output also reminds the model that daily and annual savings need to be presented in dollars. This version of the prompt produced the expected output.
 |
| Figure 9 |
After just two iterations, the results were promising. However, prompts are ideally tested on a battery of examples. The two prompts were tested on the set of five examples described in Table 1. Examples 1-3 mix dollars and cents. Example 4 mixes total cost per day and the total cost per meal. Example 5 does the same while mixing dollars and cents too.
 |
The total score for each prompt comes from adding the scores for the individual examples. The first prompt (V1) scored 40% while the second prompt (V2) scored 100%! Table 2 shows the detailed scoring for each test.

- Half of Example 1 is wrong because the output savings is not in dollars.
- In Example 2, the letters associated with each choice are flipped, and choice (b) is listed before choice (a). See Figure 10 for details. ChatGPT outputs the wrong letter (a) and calculates 0 zero savings. The prompt was apparently confused by the choices not following alphabetical order.
- All of Example 3 is wrong because the model outputs a blob of Python code instead of numbers.
- Example 4 is fully correct.
- Example 5 partial credit is awarded because the units are wrong.
 |
| Figure 10 |
How is V2 guiding to model to get the right answer every time? The prompt is is spurring ChatGPT to write it's own robust Python code that gets the right answer every time. At the end of the code blob (Figure 11), the model is producing is constructing a dictionary in the desired output format.
 |
| Figure 11 |
If this prompt were included in an a user-facing app, the tests should be repeated periodically to make sure that there is no regression in performance as the prompt or underlying LLM changes. If V2 begins to fail as further examples were added, the decision to e.g., standardize the currency amounts to dollars might have to be made.
Conclusion
This article has demonstrated important strategies in designing prompts for ChatGPT LLMs.
- Helpful tactics for improving prompts include providing clear and specific instructions, using delimiters (e.g., ```) to mark user input, telling the model to work through explicitly defined steps, and asking for structured output.
- Prompt development is iterative and is best done in a systematic, test-driven way. Test criteria can be explicitly as shown here. It is also possible to have the LLM grade it's own response (not discussed here).
- For prompts under active development, tests should be re-run periodically to prevent regressions in system performance.
- Tuning applications of LLMs is very different from the process needed for other AI models.
Hopefully this article helps and inspires you to start building new applications with ChatGPT!